opencv
当你的opencv引用出问题的时候
请记住
pip install opencv-contrib-python
顺便一提
opencv是这个
pip install opencv-python
opencv
当你的opencv引用出问题的时候
请记住
pip install opencv-contrib-python
顺便一提
opencv是这个
pip install opencv-python
对小批量(mini-batch)的2d或3d输入进行批标准化(Batch Normalization)操作
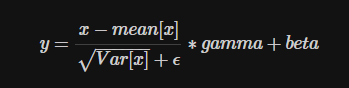
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)
在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证时,训练求得的均值/方差将用于标准化验证数据。
参数:
Shape: - 输入:(N, C)或者(N, C, L) - 输出:(N, C)或者(N,C,L)(输入输出相同)
对深度可分离卷积的代码理解
对单个通道卷积,然后在加一个点卷积
利用分组卷积实现,就相当于分组为一的分组卷积。
如何同时遍历两个字典
1.以key同时遍历两个字典(两个字典长度一样,否则以最短的次数输出)
dict_map = {1:'hello', 2:'world'}
dict_map1 = {3: 'hi', 4: 'test'}
for key1, key2 in zip(dict_map.keys(), dict_map1.keys()):
print(key1, dict_map[key1], key2, dict_map1[key2])
2.以key、value同时遍历两个字典(两个字典长度一样,否则以最短的次数输出)
dict_map = {1:'hello', 2:'world'}
dict_map1 = {3: 'hi', 4: 'test'}
for (key, value) in zip(dict_map.items(), dict_map1.items()):
print(key, value)
3.逐项同时遍历两个字典(两个字典长度一样,否则以最短的次数输出)
dict_map = {1:'hello', 2:'world'}
dict_map1 = {3: 'hi', 4: 'test'}
for kv in zip(dict_map.items(), dict_map1.items()):
print(kv)
简单介绍一下这个数据集的坑吧
首先gtfine为标签,leftimg8bit为图片
gtfine里有五种文件
color彩图,instanceid用于实例分割,labelid用于语义分割,labeltrainid可用于训练,json文件,但是之后会很麻烦,因为cityscapes提供的eval脚本只能用于labelid。
然后还有五个list文件
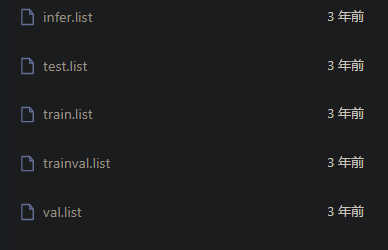
如果你够强,自己生成这5个list也行,当然也有别人搞好的list文件
同时我觉得最好看一下list里是个啥,有的拿labelid训练,有的拿trainid训练。只能说别用trainid训练,会变得不幸。
然后再给用paddleb的bml的提个醒:
第一,完整路径是没法作为绝对路径使用的,如果要看的话最好是用shell pwd一下,然后你大概就知道把完整路径中的哪部分删掉就能用了。
第二,如果你非常不幸的遇到了需要一一对应的情况,然后发现总有莫名其妙有多个对应的时候,bml有时会有checkpoint文件,而且是不可见的,这个时候建议查一下文件夹里有啥,然后精准对应一下。
第三,有的时候静态图转化需要指定输入大小,不然没法导出,具体原因不知道,如果有知道的可以告诉我一下为什么这么设计。
glob模块的主要方法就是glob,该方法返回所有匹配的文件路径列表,该方法需要一个参数用来指定匹配的路径字符串(本字符串可以为绝对路径也可以为相对路径),其返回的文件名只包括当前目录里的文件名,不包括子文件夹里的文件。
比如:
glob.glob(r'c:*.txt')
我这里就是获得C盘下的所有txt文件
os.path.join()函数:连接两个或更多的路径名组件
import os
Path1 = 'home'
Path2 = 'develop'
Path3 = 'code'
Path10 = Path1 + Path2 + Path3
Path20 = os.path.join(Path1,Path2,Path3)
print ('Path10 = ',Path10)
print ('Path20 = ',Path20)
**输出**
Path10 = homedevelopcode
Path20 = home\develop\code
如果对象具有给定的命名属性,则该hasattr()方法返回 true,否则返回 false。
class Person:
age = 23
name = "Adam"
person = Person()
print("Person's age:", hasattr(person, "age"))
print("Person's salary:", hasattr(person, "salary"))
# Output:
# Person's age: True
# Person's salary: False
注解,可以看作是对 一个 类/方法 的一个扩展的模版,每个 类/方法 按照注解类中的规则,来为 类/方法 注解不同的参数,在用到的地方可以得到不同的 类/方法 中注解的各种参数与值
Image模块的convert()
我们知道PIL中有九种不同模式。分别为1,L,P,RGB,RGBA,CMYK,YCbCr,I,F。
1、 模式“1”
模式“1”为二值图像,非黑即白。但是它每个像素用8个bit表示,0表示黑,255表示白。下面我们将lena图像转换为“1”图像。
2、 模式“L”
模式“L”为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。在PIL中,从模式“RGB”转换为“L”模式是按照下面的公式转换的:
3、 模式“P”
模式“P”为8位彩色图像,它的每个像素用8个bit表示,其对应的彩色值是按照调色板查询出来的。
4、 模式“RGBA”
模式“RGBA”为32位彩色图像,它的每个像素用32个bit表示,其中24bit表示红色、绿色和蓝色三个通道,另外8bit表示alpha通道,即透明通道。
5、 模式“CMYK”
模式“CMYK”为32位彩色图像,它的每个像素用32个bit表示。模式“CMYK”就是印刷四分色模式,它是彩色印刷时采用的一种套色模式,利用色料的三原色混色原理,加上黑色油墨,共计四种颜色混合叠加,形成所谓“全彩印刷”。
6、 模式“YCbCr”
模式“YCbCr”为24位彩色图像,它的每个像素用24个bit表示。YCbCr其中Y是指亮度分量,Cb指蓝色色度分量,而Cr指红色色度分量。人的肉眼对视频的Y分量更敏感,因此在通过对色度分量进行子采样来减少色度分量后,肉眼将察觉不到的图像质量的变化。
7、 模式“I”
模式“I”为32位整型灰色图像,它的每个像素用32个bit表示,0表示黑,255表示白,(0,255)之间的数字表示不同的灰度。在PIL中,从模式“RGB”转换为“I”模式是按照下面的公式转换的:
8、 模式“F”
模式“F”为32位浮点灰色图像,它的每个像素用32个bit表示,0表示黑,255表示白,(0,255)之间的数字表示不同的灰度。在PIL中,从模式“RGB”转换为“F”模式是按照下面的公式转换的: